Compressie
Algemeen (Compressie)
2BGM: TVstudiotechnieken / 2005_2006 / Laatste aanpassing op 2006-09-23.
Begint compressie van het signaal al bij de keuze
van het sample systeem bv. 4:2:2 of 4:2:0?
Ja
Klopt het dat DCT en Wavelet zijn manier om een signaal te ordenen en dat ze
geen compressie uitvoeren?
Ja
Klop het dat de eigenlijke compressie wordt gedaan door de weging van de door
de DCT of wavelet geordende frequenties
en dat het de bedoeling is bij deze weging om doormiddel van een delingsfactor
voor de lage frequenties zoveel 0-en te krijgen?
De weging zal zo de uiteindelijke compressiefactor
bepalen, maar de eigenlijke compressie wordt bekomen door de verschillende
technieken binnen de Bitrate reduction.
En dat hoe groter de delingsfactor hoe meer 0-en
er zijn maar hoe moeilijker het wordt om informatie correct te herwinnen
en er is dus een groter verlies is?
Ja
Klopt het dat de aantal windows bij wavelet wordt bepaald door deze
delingsfactor en dat hoe minder windows je gebruikt hoe slechter de kwaliteit
gaat zijn?
Klopt het dat deze delingsfactor wordt doorgestuurd en bij de encoder gebruikt
wordt om het signaal te herwinnen.
Dit klopt ongeveer, maar er
rest me vandaag spijtiggenoeg niet voldoende tijd om dit proper in een mail
uiteen te zetten.
Klopt het als ik zeg dat Tijdsredundantie ook een manier van compressie is die
werkt met i-p en b beelden en zo comprimeert. Dat tijdsredundantie los staat
van DCT en wavelet en weging?
Ja
Klopt het dan als ik zeg dat jpeg, mpeg en h264/avc tools zijn die
verschillende van de hierboven beschreven technieken toepassen om zo een
gecompresseerd beeld te verkrijgen?
Ja
Zou u er mij op kunnen wijzen als ik hier iets over het hoofd heb gezien als
er hier iets niet klopt.
Aan de hand van je vragen kan ik niet weten of je zaken
over het hoofd hebt gezien, maar de meeste van je redeneringen lijken wel OK.
Algemeen (Compressie)
2BGM: TVstudiotechnieken / 2007_2008 / Laatste aanpassing op 2008-05-24.
Videocompressie Algemeen
Is het correct om te stellen dat het algemene principe van videocompressie
als volgt kan worden omschreven:
In de eerste plaats doen we bij compressie aan redundantiedetectie, we beperken de
hoeveelheid data waarop we lossy compressie zullen toepassen. Door
tijdsredundantie beperken we het aantal beelden bij de doorsturing
(Neen: het aantal beelden wordt niet beperkt, het blijven er 25/sec) de hoeveelheid informatie door te
werken met motion estimation en door transmissie van enkel de werkelijke
verschillen in de opeenvolging van beelden (GOP-structuren). Door
ruimtelijke redundantie delen we een beeld op in zijn
frequentiecomponenten (toegepast op beperktere sample-blocks) waarvan we
de hoge frequenties (details in beeld) het meest kunnen missen. Aan de
hand van weging geven we een groter gewicht (waarde) aan de lagere
frequenties en een kleiner gewicht aan de hoge. Op wat overblijft passen
we Bit Rate Reduction-technieken toe als VLC en RLC.
Compressie: GOP & Profiles (Compressie)
2BGM: TVstudiotechnieken / 2004_2005 / Laatste aanpassing op 2014-06-01.
tijdens het studeren van jouw curcus, zijn een paar dingen nog niet echt duidelijk.
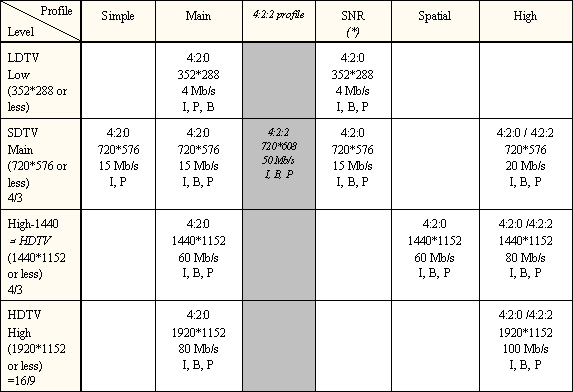
in het hoodstuk video compressie kom ik een paar keer de term : GOP=1;4:2:2P@ML of GOP=2;4:2:2P@ML
GOP versta ik dat is group of picture in een I,P en B structuur, maar wat betekent " = 1 of =2 "??
Dat wil zeggen dat de GOP 1 of 2 is. Een veel gebruikte GOP is ook 12.
Dat wil zeggen dat er dan 1, 2 of 12 beelden in een GOP zitten.
dan komt er 4:2:2 dat is de verhouding voor de sampling freq voor Y:U:V maar hier achter komt dan P@ML hier van vind ik de betekenis ook niet terug.
4:2:2P wil zeggen: 4:2:2 profile
@ wil zeggen bij
ML wil zeggen main level
Welke de profiles en levels zijn, staat in onderstaande figuur.
ook nog bij digitale tapeformaten staat op pagina 130 van de cursus dat HDCAM ongecompresserd opneemt maar in de les over HD meen ik mij te herinneren dat enkel de norm D6 ongecompresserd HD opneemt, en dat HDCAM weldegelijk een compressie doorvoert!?
Je hebt gelijk. Het is inderdaad een gecompresseerde norm, aan 8 bit ipv 10 bit.
Contributie (Compressie)
1PB: Technologie Basis 1 / 2022_2023 / Laatste aanpassing op 2023-12-26.
´Ik heb twee vraagjes over de cursus; op pagina 193 (bij de dia over compressie algoritmes & GOP) heeft u het over contributietoepassingen en hoe tijdsredundantie hierin vermeden wordt. Wat bedoelt u precies met contributietoepassingen?
[LB] Contributie is het uitwisselen van beelden tussen zenders, facilitaire bedrijven, ...Distributie is het soorsturen van beelden naar de particulieren, huishoudens.
DCT (Compressie)
AK Cine 3: Beeldtechnologie 2 / 2021_2022 / Laatste aanpassing op 2022-06-17.
Bij DCT compressie wordt elk beeld verdeelt in hokjes van 64 pixels. (8*8)
Is het elk hokje die wordt aangemaakt, een samenstelling van die 64 cosinus wave pixels.
of is het elk van die 64 pixels een samenstelling van een cosinus wave?
Elke block wordt aangemaakt door een set van DCT-resultaten.
De pixels maken deel uit van de block, maar het is deze laatste die de DCT ondergaat.
DCT & DWT (Compressie)
2BGM: TVstudiotechnieken / 2013_2014 / Laatste aanpassing op 2014-06-01.
Ruimtelijke redundantie:
DCT/Wavelets/DWT 'Wavelets' moet niet extra worden aangehaald, omdat DWT de 'digitale' vorm is van de wavelet-berekeningen
DCT:
1. Voor ruimtelijke redundantie bij DCT toe te passen dient men eerst het beeld op te delen in aparte deelbeelden (doorgaans 8x8 pixels = sampleblock)
2. Vervolgens voert men DCT uit waardoor het signaal gespiegeld wordt en we kunnen werken met een 8x8 coëfficiëntsblok die toelaat om met de frequentie inhoud te werken (transformatie van tijdsdomein naar frequentiedomein)
Het spiegelen is een wiskundige stap binnen de DCT die er voor zorgt dat berekeningen eenvoudiger kunnen worden uitgevoerd. Het resultaat van de DCT geeft de frequentiecomponenten van de 8*8 pixelblok.
Omdat we nu de frequentie inhoud beschikbaar hebben is het mogelijk om frequenties/deelbeelden met de fijnste details weg te laten en zo te compresseren.
3. Of er nu wel of niet gecompresseerd is, men dient inverse DCT toe te passen om de coëfficiëntsblok terug om te zetten naar een sample block. Zonder compressie zal deze een exacte replica zijn (Loss-less) tegenover gecompresseerd (Lossy)
Door de resultaten van de DCT te interpreteren kan men bits weg laten. Als bepaalde frequentiecomponenten niet aanwezig zijn, is het resultaat voor die component 0, en kan dus eenvoudig worden weggelaten. Dit weglaten van de '0'-gegevens zorgt voor compressie, maar zonder dat detail wordt verloren; lossless.
Als bepaalde waarden die in de buurt van '0' liggen worden weggelaten, of bepaalde waarden worden weggelaten omdat die details niet nodig zijn/kunnen doorgestuurd worden is er lossy compressie.
Wavelets/DWT:
Hiervoor kiest men ervoor om het signaal op te delen in verschillende frequentiebanden (zie fig. DWT pg. 84 Sorry, ik heb geen geprinte cursus met paginanummers, en kan dus niet naar die figuur refereren). Men kan er nu voor kiezen om heel de bandbreedte door te sturen (hoge resolutie) of slechts bepaalde delen beginnend vanaf de laagste frequenties (hoe minder delen, hoe lager de resolutie).
Er dient nog wel een DWT te worden berekend op de deelbeelden.
DCT vs DWT (Compressie)
2BGM: TVstudiotechnieken / 2005_2006 / Laatste aanpassing op 2006-06-25.
> Ik ben net bezig met het hoofdstuk
compressie, en ik vroeg me iets af.
> Ten eerste, is volgende stelling correct:
>
> DCT gaat op zoek naar correlatie tussen een bepaald (te compresseren) signaal,
of beter, een fragment daarvan, en cosinusfuncties met verschillende
frequenties en levert een curve die in feite de correlatie tussen elk van
die cosinusfuncties en het originele signaal voorstelt en tevens het
frequentiespectrum van het signaal is.
Het opzoeken van de
correlatie geeft geen curve, maar geeft afzonderlijke getallen voor de
verschillende harmonischen van de grondfrequentie.
> Ten tweede, kan ik stellen: wavelettransformatie doet in feite hetzelfde, maar
met een zorgvuldig gekozen functie.
Ja, maar er wordt gebruik gemaakt van een intelligentere functie dan de sinus, en de schaling en de verplaatsing zijn 'efficiënter' dan bij de fourrieranalyse
> Kan ik daaruit afleiden dat DWT eigenlijk goed lijkt op fourieranalyse?
Ja.
>En wat is dan eigenlijk het essentiële verschil met fourieranalyse?
Is het correct te zeggen dat, doordat we de
wavelet in de tijd verplaatsen,
we de veronderstelling dat het signaal periodiek is loslaten en daardoor
ook de tijdsfactor in rekening kunnen brengen, maw dat we beter in kaart
kunnen brengen wanneer welke componenten voorkomen?
Vooreerst: compressie bij video
gebeurt op basis van de beelden, wat tijd dus is bij de 'gewone' DWT,
is positie in het beeld bij video.
De vorm van de wavelets is zo dat ze inherent rekeing
houden met het feit dat de grootte van de wavelet niet overeenkomt met
de grootte van het beeld. Dit heeft te maken met de 'windowing'.
Dit is niet zo bij de DCT, waar de cosinusfunctie, met dewelke dus
vergeleken wordt, deze windowing niet 'ingebakken' heeft.
Ten tweede is er de schaling.
Bij de DCT worden fijne details
met een even grote nauwkeurigheid geplaatst als grovere. De DWT gaat op
dit gebied intelligenter te werk: fijne details worden beter geplaatst dan
grove. Zo kan met eenzelfde hoeveelheid data een betere kwaliteit worden
aangegeven.
de-noisen (Compressie)
1PB: Technologie Basis 1 / 2022_2023 / Laatste aanpassing op 2023-12-26.
Ook op pagina 196 (bij de dia over compressiefouten en ruis & grain) zie ik de-noisen staan, maar heb tot nu toe geen idee wat dat precies inhoudt. Ook het verschil tussen encoder en decoder is me niet helemaal duidelijk.
[LB] De-noisen is het weghalen van ruis. De encoder is het toestel of de software die compresseert, en dus van ongecompreseerde video gecompresseerde video maakt. De decoder decodeert gecompresseerde video en maakt er terug gewone video van.
DWT (Compressie)
2BGM: TVstudiotechnieken / 2005_2006 / Laatste aanpassing op 2006-06-25.
p 90) DWT; dynamic wavelet transform
worden gebruikt om het aantal redundante gegevens te verminderen, doordat er
slechts bepaalde schalingen gebeuren en bepaalde tijdsverschuivingen. Moet ik
dat dan interpreteren zoals een "sampling" van een continue functie?
De 'D' staat voor Discrete, wat inhoudt dat er enkel op
vaste waarden een sample genomen worden. je kan het ook vergelijken met de
Fourrier analyse en de Dicrete Fourrier analyse. De gewone fourrier
analyse doet de analyse op de originele (continuë) functie. De Discrete Forrier
analyse is een herwekte vorm van de Fourrier analyse die geoptimaliseerd is voor
de verwerking van gesampelde signalen.
DWT (Compressie)
2BGM: TVstudiotechnieken / 2005_2006 / Laatste aanpassing op 2006-06-25.
Bij die wavelets, snap ik het principe wel maar dan komt DWT en CWT hierbij.
Bij CWT praat men over een verschuiving. Is dit de verschuiving die gebeurd bij het windowen?
Het windowen is een techniek die nodig is om zo goed als mogelijk is een (niet periodiek) signaal te transformeren met de DCT of de DWT.
De verschuiving gebeurt om de wavelet zo goed mogelijk op het originele signaal te passen, net zoals bij de de fourrier analyse de sinus (of cosinus functie) er een fase wordt gegeven (is eigenlijk ook een verschuiving).
GOP (Compressie)
2BGM: TVstudiotechnieken / 2013_2014 / Laatste aanpassing op 2014-06-01.
Nog een korte vraag over Betacam IMX/D10:
"Dit is de meest recent digitale SD norm van Sony (2000). Deze werkt met een GOP=1, bij 4:2:2@ML.
Slaagt GOP=1 op 1 seconde voor heel de GOP structuur af te werken? (IBBPBBPBBPBBI = 1 seconde)
GOP=1 wil zeggen dat de hele GOP slechts uit 1 frame bestaat, dus I-frame only.
GOP (Compressie)
2BGM: TVstudiotechnieken / 2014_2015 / Laatste aanpassing op 2015-06-03.
Is het correct om te stellen dat als je een group of pictures doet eindigen met een P-beeld, dat de GOP dan gesloten is. En dat de GOP doen eindigen met een B-beeld altijd voor een open GOP zorgt?
Op dit moment vind ik niet onmiddellijk een tegevoorbeeld uit de praktijk, maar de definitie van Gesloten Gop is: een groep van beelden waarvoor je voor het decoderen van de beelden geen info nodig hebt uit de volgende GOP.
En daarnaast vroeg ik me het volgende af: in de figuur omtrent GOP wordt eerst een reeks genummerde frames gegeven, daaronder hoe ze gecodeerd worden (I B B P B B P B B I). Dan daaronder staat de sequentie van de datastream, waarbij de I, P en B beelden van plaats verschuiven ( I P B B P B B I B B). Waarom verschuiven deze?
Om te coderen en te decoderen zijn de beelden nodig in de volgorde I P B B P B B I B B want om een B beeld uit bv de sequentie I B B P te bekomen heb je eerst het I- en het P-beeld nodig voordat je de B-beelden kunt berekenen. Om de decoder zo eenvoudig mogelijk te houden, zal de coder ze ook in die volgorde uitsturen.
GOP (Compressie)
1PBAK: Technologie 1 / 2019_2020 / Laatste aanpassing op 2020-05-30.
In de GOP (p214-215): als de B-frame gaat vergelijken met de I-frame wordt er gezegd dat enkel het verschil tussen de B-frame en de
I-frame gecomprimeerd wordt. Is het niet logischer dat net hetgene dat niet verschilt met de vorige frame gecomprimeerd wordt? [LB] Als je gaat comprimeren wat niet verschilt, moet je dat ook niet doen, want het geeft geen bijkomende informatie. Als je laat vallen was is veranderd, ga je bv. ook niet de beweging in de videobeelden zien. In vorige slides stond er namelijk dat hetgene wat niet veranderd beter gecomprimeerd wordt aangezien de kijker hier minder aandacht aan besteed... [LB]Als iets niet veranderd, moet je het niet doorsturen, en kan je het dus weg laten, wat dus een grotere compressie oplevert. Maar als je, zoals je eerst voorstelde de veranderingen ook gaat weg laten, heb je maar één beeld en daarna geen veranderingen meer, wat dus eigenlijk een foto is.
GOP (Compressie)
AK Cine 3: Beeldtechnologie 2 / 2021_2022 / Laatste aanpassing op 2022-06-17.
Ik heb de functie op mijn Canon r5 om Long GOP te shooten.
Ik heb nog nooit problemen gehad bij het monteren hiervan. Ik kan elke frame weghalen zonder dat ik datamoshing genereer. Dus ook I-frames.
Waarom wordt hier dan in de cursus over gesproken dat dit niet voor editing bedoelt is? Daarbij vraag ik me af hoe het laatste encoding proces exact werkt. Waarbij IBBP verwisseld worden in IPBB. ( zodat het decoding systeem niet voorwaarts in de tijd moet )
[LB] Als je monteert wordt het gecompresseerde beeld eerst terug omgezet naar een uncompressed bestand. Je monteert dus uncompressed.
Een long-gop compressed beeld omzetten naar uncompressed is rekenintensiever: het hele GOP moet worden gedecodeerd en terug worden gecodeerd. Bij I-frame only video moeten enkel de beelden die door montage worden aangepast worden herrekend.
Het omwisselen van de IPBB-IBBP volgorde gebeurt ´achter de schermen´ van je montagesoftware, en zie je dus niet bij het editen.
Datamoshing kan je dus niet doen met gewone editing software. Je moet daarvoor software gebruiken die in de (compressed) datastream gaat werken, niet in (uncompressed) videobeelden.
Stel nu iemand springt van de grond en land terug in 4 frames. (fictief) De I frame is de reëel opgenomen man in de lucht. De B en B frames bereken de verschillen tussen de I-frame en de P-frame. De P-frame het verschil van zichzelf met de B frame. De laatste encoding draait het om waardoor het beeld begint met man in de lucht, P frame: man op de grond en dan 2 B frames van de man die landt. Niet echt syncroon dus. Betekent dat dan dat die beelden tijdens het encoden nog niet gevisualiseerd worden en alles dan gebasseerd is op de I-frames en er dus niet echt een verschil is tussen P en B frames?
[LB] Zie het einde van het vorige antwoord.
Harmonischen (Compressie)
2PBAK: Videotechnologie 2 / 2019_2020 / Laatste aanpassing op 2020-05-19.
Waarom moeten we bij het doorsturen van een digitaal signaal minstens 3 harmonischen hebben? Zie Signaaltechnologie vorig jaar.
Bij fourieranalyse is gezien dat een willekeurige golfvorm kan worden omgezet in een grondtoon en harmonischen, maar ook dat een grondtoon en harmonischen optellen een complexere golf kunnen aanmaken.
Voor een blokgolf (eentjes en nulletjes) is de derde harmonische (3θ) nodig.
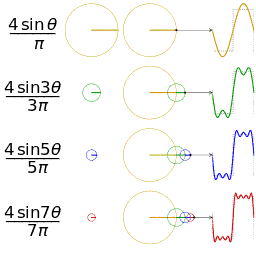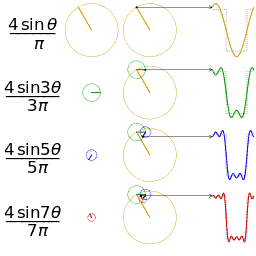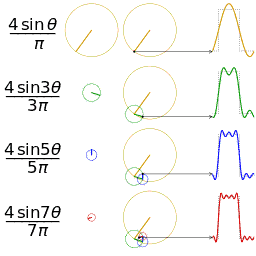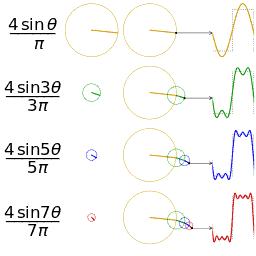
MP@ML (Compressie)
2BGM: TVstudiotechnieken / 2005_2006 / Laatste aanpassing op 2006-09-23.
-Als laatste. Ik had tijdens de les bij MP@ML
geschreven dat dit een compressiestandaard is die gebruikt word voor het
verdelen tussen productiehuizen. Klopt dit, want veel vindt ik hiervan niet
terug
Dit klopt niet. De kwaliteit is er voor te laag
(4:2:0).
Wat daar meer voor gebruikt wordt is 4:2:2P@ML.
Kijk ook eens in de FAQ op m'n website, 2BGM/Compressie/GOP & Profiles.
Hier een klein overzichtje:
Prediction error (Compressie)
2BGM: TVstudiotechnieken / 2005_2006 / Laatste aanpassing op 2006-06-25.
> * Compressie: in H.264/AVC: wat wordt er precies bedoeld met de prediction
> error? Ik begrijp niet hoe de coder kan weten wat de fout zal zijn die hij
> maakt in zijn voorpselling van de beweging en wat het nut is van die door te
> sturen in plaats van ze te corrigeren (dus ik veronderstel dat ik het
> concept gewoon verkeerd begrepen heb)...
Als de encoder een compressie doet, dan weet deze welke info er zal doorgestuurd worden en dus ook hoe het beeld er na decoding zal uit zien. Het verschil hiertussen en het originele beeld is dus de error.
De prediction error is dus het verschil tussen het originele beeld, en het beeld zoals dat wordt bekomen na het opstellen van oa de P-beelden.
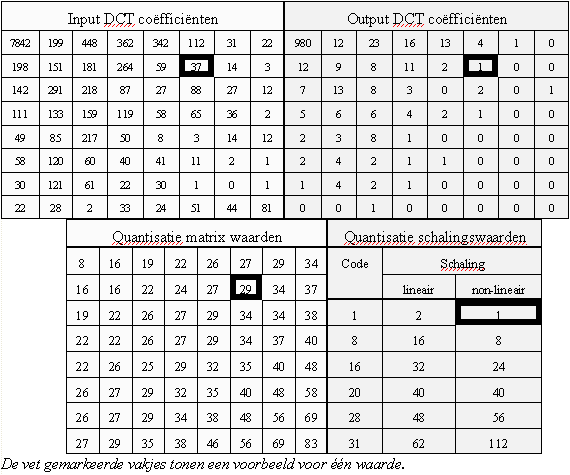
Quantisatie (Compressie)
2BGM: TVstudiotechnieken / 2007_2008 / Laatste aanpassing op 2008-05-24.
de waarden in de tabel van (quantisatie matrix waarden), is dit de hoeveelheid stappen die worden genomen bij die frequenties
of is dit de grote van de stap bvb
bij de laagste frequentie coeff wa: 7842 wordt die gequantificeerd in 8 stappen of wordt deze x aantal keer gequantificeerd met
een stapgrootte van 8.
deze laatste lijkt mij de meest correcte methode om de theorie te doen kloppen. maar ik wil even checken
In dit voorbeeld is 7842 één van de resultaten van de DCT van een 8*8 pixel blok.
Het is de DCT die de frequentiecomponenten van het beeld opzoekt in de 8*8 pixelblok. De manier waarop dit gebeurt ligt
wiskundig vast.
Deze waarde wordt daarna gedeeld door de waarde 8 uit de quantisatie matrix. Hoe groter deze waarde is,
hoe hoe minder naukeurig de benadering, maar ook hoe meer kans deze deling de waarde 0 oplevert.
Quantisatiematrix (Compressie)
2PBAK: Videotechnologie 2 / 2019_2020 / Laatste aanpassing op 2020-06-21.
Mij is de Wavelet Transform nog steeds niet zo duidelijk hoe dit werkt. Kan u hier een simpelere uitleg voor geven?
Zo´n algemene vraag is moeilijk via mail te beantwoorden.
Kan je specifieker zijn, of lees dit eens na.
https://georgemdallas.wordpress.com/2014/05/14/wavelets-4-dummies-signal-processing-fourier-transforms-and-heisenberg/
De website heeft het inderdaad wel wat duidelijker gemaakt.
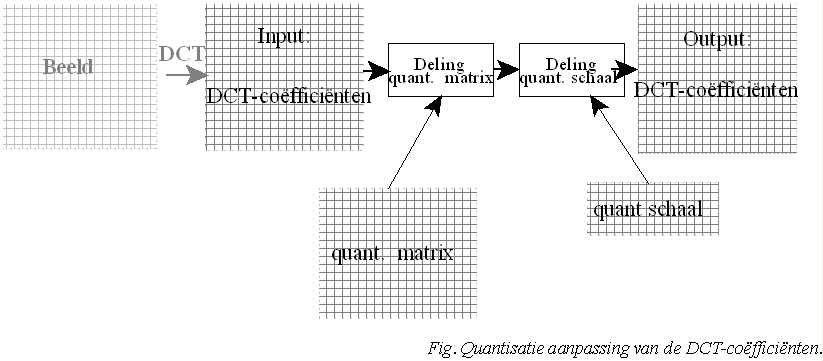
Nu zit ik wel nog met een andere vraag bij de weging die wordt toegepast na de DCT wordt er zowel gebruikt gemaakt van 2 tabellen (quantisatie matrix waarden & quantisatie schalingswaarden).
Wat is het verschil hier juist tussen en hoe worden deze toegepast?
De matrix geeft het belang aan van de individuele DCT-coëfficënten. Zo geven ze aan dat de fijnere details minder van belang zijn dan de grovere structuren.
De waarde van de getallen in de matrix liggen vast bij een gekozen compressiemethode in je softwarepakket.
Als je dan de compessieratio wil aanpassen (bij CBR), of een bepaalde kwaliteit wil bekomen (bij VBR), wordt ingegrepen via de schalingswaarden.
Het resultaat van de DCT, gedeeld door de matrixwaarden, wordt dan opnieuw gedeeld door de schaling.
Als gedeeld wordt door 1 is er geen extra compressie, als die deelfactor oploopt, is er bijkomende compressie.
Tijdsredundantie (Compressie)
1PBAK: Technologie 1 / 2019_2020 / Laatste aanpassing op 2020-06-03.
Ook snap ik tijdsredundantie niet zo goed. [LB] Tijdsredundantie is het gebruik maken van de gelijkheid tussen twee opeenvolgende beelden bij compressie. Als een (gedeelte van een) beeld in een film of video hetzelfde is als het vorige beeld, moet dit niet opnieuw worden doorgestuurd, en kan je dus aan compressie doen.
Wavelets (Compressie)
2BGM: TVstudiotechnieken / 2014_2015 / Laatste aanpassing op 2015-06-03.
Ik kan me momenteel niet voorstellen wat een wavelet juist is. Ook weet ik niet zo goed wat het verschil is tussen de wavelet en de windowing. Windowing is de techniek om uit een grote reeks gegevens een deel uit te nemen die te verwerken. (bv. een macroblok uit een beeld, 1024 audio samples uit de stream van audio, ..) Bij video waveletcompressie gaat men over het gehele beeld de overeenkomst zoeken. Is de wavelet u signaal en de windowing de samples van u signaal. Want als ik het goed heb dan gaat men bij DWT het signaal toch opsplitsen in frequentiebanden net zoals bij de fourieranalyse gebeurt. Neen, bij DWT wordt niet opgesplitst in frequentiebanden, maar in resoluties. Ik heb de FAQ al een aantal keer bestudeerd, maar ik begrijp het nog altijd niet goed.
Weging (Compressie)
2BGM: TVstudiotechnieken / 2005_2006 / Laatste aanpassing op 2006-06-25.
p93 bij weging, onder de tabel)
Waarschijnlijk een stomme vraag, maar hoe kan men nullen bekomen door te delen?
Men krijgt toch nooit een nul door te delen?
Door afronding (naar beneden) van het resultaat van de
deling.
Weging (Compressie)
2BGM: TVstudiotechnieken / 2005_2006 / Laatste aanpassing op 2006-06-25.
Men zegt eerst in de uitleg: 'Om een reductie van data te doen kunnen we details weglaten.'
Iets later in de uitleg gebeurd het volgende. 'De gegevens van de data worden dus gerangschikt volgens de frequentienhoud. We hebben dus evenveel gegevens voor als na de DCT.' Later spreekt men ook nietmeer van weglaten van gegevens,maar alleen van rangschikken van gegevens.
Wat zorgt hier nu voor de compressie, is dit weglaten van gegevens(lossy) of rangschikken van gegevens(lossles)? Zie ik hier iets boven het hoofd?
Compressie heb je door het weg laten van data.
Door de DCT worden de gegevens gerangschikt volgens resolutie, lage resolutie eerst, fijne details laatst.
Na dit rangschikken wordt de data doorgestuurd voor zover er voldoende bitrate is, met de grovere details eerst. Als er niet genoeg ruimte is, worden de laatste data (fijnere details) niet meer doorgelaten. Hierdoor is er dus compressie.
Dit is wel niet de beste manier om aan compressie te doen. Het wegvallen van gegevens geeft heel duidelijke fouten in beeld. Beter is er voor te zorgen dat door de schaling (quantisatie) in de compressie de output tabel voldoende coëfficienten heeft die 0 zijn. Die moeten sowieso niet worden doorgestuurd. Je krijgt meer nullen door hogere waarden te nemen in de quantisatie matrix, maar het is gebruikelijker en beter door de quantisatieschaal aan te passen.
Weging (Compressie)
2BGM: TVstudiotechnieken / 2007_2008 / Laatste aanpassing op 2008-05-24.
na het uitvoeren van een DCT, wordt er gezegd dat in de coeff. die de lage frequenties voorstellen, de meeste visuele beeldinhoud weergeven. dus in de tabel (input dct coeff) de vakjes linksboven. (dct verdeeld de coeff volgens spectrale inhoud) bij weging gaan we ervan uit dat die coeff met lage frequenties best fin gequantiseerd worden. maar moet dan niet in de tabel van (quantisatie matrix waarden) niet linksboven de hoogste factor hebben? als die coeff dan toch het fijnste moet gequantiseerd worden?
=> De grote waarden in de quantisatietabel zal waarden uit de DCT sneller doen naar 0 gaan, omdat delen door een groot getal een kleiner resultaat oplevert.